Refinement of Pseudo-Labels in Unsupervised Domain Adaptation Using SAM2
Overview
When a robot (or any vision system) is trained in one environment and then deployed in another, its perception quality often drops sharply due to domain shift: the deployment data distribution differs from the training distribution (different sensors, lighting, scene layout, textures, etc.).

Baseline pseudo-label projection
|

SAM-refined pseudo-labels
|
This project targets semantic segmentation in robotics, and specifically Unsupervised Domain Adaptation (UDA) where the target domain is unlabeled. In UDA, a common strategy is to create pseudo-labels (labels predicted automatically) and use them as supervision to adapt the model.
What is Unsupervised Domain Adaptation (UDA)?
Unsupervised Domain Adaptation is the problem of adapting a model from a labeled source domain (where you have annotated data) to an unlabeled target domain (where you have no annotations), while the input distribution changes due to domain shift.
In practice, this typically means:
- You train on one dataset (source) with ground truth.
- You deploy on a different environment/dataset (target) with no labels.
- You improve performance on the target domain by leveraging structure in the data (e.g., pseudo-labeling, consistency, or multi-view/3D constraints) instead of manual annotation.
Why UDA is important
UDA is crucial in robotics because deployment environments change constantly, and collecting pixel-level labels for every new home/office/scene is slow and expensive. A robust UDA pipeline can:
- Reduce or eliminate the need for new annotations.
- Enable faster deployment in unseen environments.
- Improve safety and autonomy by maintaining reliable perception under changing conditions.
The core idea of this work is:
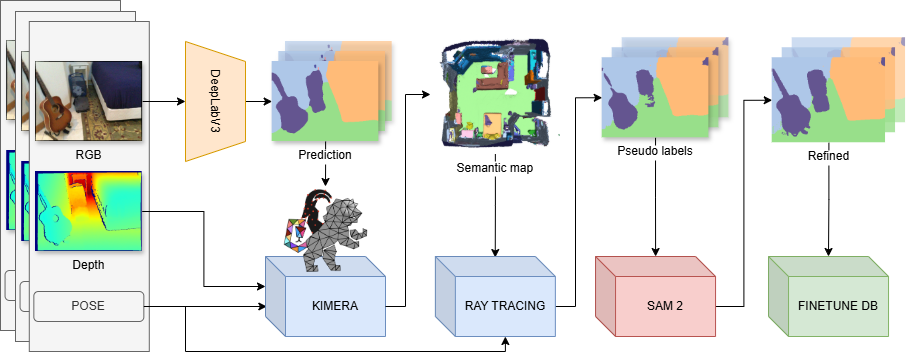
- Start from an established 2D–3D UDA pipeline that generates pseudo-labels by fusing 2D predictions into a 3D semantic map.
- Improve those pseudo-labels by adding a refinement stage based on the Segment Anything Model (SAM2), a strong zero-shot segmentation foundation model.
The method improves boundary accuracy and reduces voxel-induced artifacts, especially when the system uses coarser 3D voxel maps for real-time constraints.
Problem Setting
Semantic segmentation for robotics
Semantic segmentation assigns a class to every pixel of an image. This kind of dense understanding is fundamental for:
- Navigation in cluttered indoor environments
- Manipulation and interaction with objects
- Building semantic maps for planning
Why domain shift is a big deal
Even modern segmentation architectures can fail to generalize when:
- The camera is different
- Lighting changes (indoor/outdoor, day/night)
- The scene composition differs (homes, offices, labs)
In robotics, manually labeling new environments is expensive and often impractical. That makes UDA particularly attractive.
Why pseudo-labels are the bottleneck
UDA systems frequently rely on pseudo-labels produced by a model trained in the source domain. Early in adaptation these pseudo-labels are noisy, and errors can propagate into training.
This work focuses specifically on a pseudo-labeling pipeline that leverages 3D mapping to enforce temporal and view consistency, but still suffers from spatial imprecision due to voxelization and projection.
Baseline Pipeline: DeepLabV3 + Kimera + Ray Casting
This project builds on the continual adaptation framework of Frey et al. (Kimera-based semantic mapping) and uses the model checkpoints and training configuration from Liu et al. (neural rendering continual UDA) as a consistent baseline.
At a high level:
- 2D segmentation: a DeepLabV3 model produces per-frame semantic predictions.
- 3D semantic fusion: Kimera integrates RGB-D frames and predictions into a voxel-based semantic map using Bayesian fusion.
- Pseudo-label projection: ray casting projects the 3D semantic voxel map back into the image plane, producing pseudo-labels aligned to each RGB frame.
- Continual learning: pseudo-labels supervise further fine-tuning to adapt to the new domain.
The main advantage is global semantic consistency: fusion reduces the impact of single-frame mistakes. The main drawback is that voxelization introduces artifacts.
Voxel Resolution Trade-off (3 cm vs 5 cm)
Voxel size is a key engineering trade-off:
- 3 cm voxels preserve more detail and object boundaries, but are heavier in memory and computation.
- 5 cm voxels are more efficient and more realistic for real-time constraints, but pseudo-labels become blocky and noisy.
Semantic voxel map quality

Semantic voxel map (3 cm)
|

Semantic voxel map (5 cm)
|
How pseudo-label projections degrade at 5 cm
Below are representative comparisons of the projected pseudo-labels produced from 3 cm and 5 cm voxel maps on the same scene. The 5 cm projection tends to lose thin structures and smear boundaries.
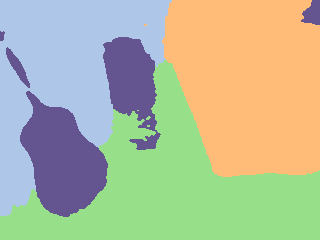 3 cm | 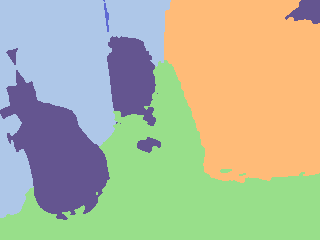 5 cm | 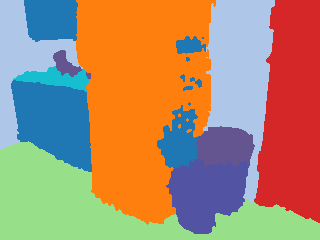 3 cm |  5 cm |
 3 cm |  5 cm |  3 cm |  5 cm |
Empirically, across evaluated scenes, using a 3 cm voxel map yields an average improvement of +1.84 mIoU over the 5 cm configuration (before any SAM refinement), but at a significantly higher computational cost.
Proposed Extension: SAM2-Based Pseudo-Label Refinement
To reduce voxel-induced artifacts while keeping the efficiency benefits of coarser maps, I introduced a refinement stage based on SAM2.
SAM2 is a zero-shot segmentation model that can produce high-quality masks when prompted. The key challenge is that SAM is not class-aware by default (it segments regions), while our goal is semantic segmentation.
This project solves it by:
- Using SAM2 to generate sharper instance-like masks.
- Transferring semantic classes from the original pseudo-labels into those masks.
- Falling back to the original pseudo-label when SAM2 doesn’t provide a mask.
Kimera pseudo-labels vs SAM-refined labels
The following examples show how SAM refinement tends to sharpen boundaries and separate objects better.
 Kimera pseudo-label |  SAM refined | 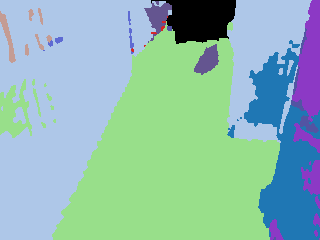 Kimera pseudo-label | 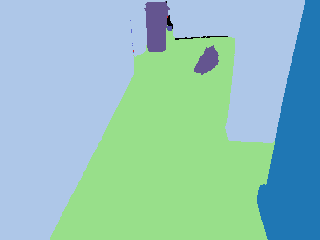 SAM refined |
 Kimera pseudo-label |  SAM refined |  Kimera pseudo-label |  SAM refined |
Prompting SAM2: Two Strategies
SAM requires prompts. The thesis evaluates two automated prompting approaches.
1) Calculated prompting (conservative)
Calculated prompting is driven by the current pseudo-label structure. For each connected component (a connected region with the same label in the pseudo-label), we compute:
- A bounding box
- A centroid (adjusted to lie on a valid pixel of the target label)
Then we apply heuristics to improve robustness:
- Erd (hereditary): if SAM leaves regions unlabeled (black / empty), copy those pixels from the original pseudo-label.
- Ns (no small): discard small connected components to reduce noise, especially in heavily fragmented “Picasso” pseudo-labels.
- nWm (no wall/floor majority fill): walls/floors can cause SAM masks that cover huge parts of the image; for such classes, avoid majority-vote filling that can catastrophically mislabel large regions.
This setup was selected after ablation studies as a strong and stable compromise.
2) Grid prompting (aggressive)
Grid prompting places a uniform grid of points over the image. Each point is used as a prompt; SAM produces multiple masks, and masks are merged (largest to smallest). This strategy:
- Reduces dependency on pseudo-label quality
- Often improves boundaries strongly
- Can fail badly in some scenes, because it relies more heavily on SAM’s raw segmentation
Visual comparison: grid vs calculated prompts

Grid prompting
|

Calculated prompting
|
Mask Fusion: From SAM Regions to Semantic Labels
Once SAM produces masks, we build the final refined semantic label map:
- For pixels inside a SAM mask, assign a semantic class using the pseudo-label distribution inside the mask (majority / consistent transfer).
- For difficult cases (e.g., walls/floors), apply safer fill logic to prevent a single over-segmented mask from dominating.
- For pixels not covered by any SAM mask, fall back to the previous pseudo-label (Erd).
This design keeps refinement improvements while preventing SAM from corrupting large regions when it fails.
Implementation Notes
The full pipeline is implemented in a modular, ROS-based setup:
- Each stage is a ROS node (segmentation inference, mapping, ray tracing, SAM refinement, and control).
- A dedicated control node handles synchronization, image flow, and communication.
Key configuration choices:
- Backbone: DeepLabV3 with ResNet-101 (PyTorch).
- Input resolutions:
- Main pipeline images resized to 320×240 for efficiency.
- SAM refinement tested at both 320×240 and original 1296×968.
- Voxel sizes: experiments run with 3 cm and 5 cm.
- Dataset: ScanNet (indoor RGB-D scenes with semantic ground truth).
Experiments
Reproducing the mapping baseline
To validate the pipeline integrity, I reproduced the mapping/pseudo-label generation step using the public checkpoint from the neural-rendering UCDA work. Results are consistent with the trends in the original paper, even if exact numbers differ slightly.
A summary on scenes 0–5 shows how pseudo-label quality depends on voxel size:
| Scene | DeepLab (mIoU) | Pseudo 5 cm (mIoU) | Pseudo 3 cm (mIoU) |
|---|---|---|---|
| 0 | 41.2 | 48.1 | 48.4 |
| 1 | 36.0 | 28.8 | 33.0 |
| 2 | 23.7 | 26.0 | 27.6 |
| 3 | 62.9 | 63.9 | 66.8 |
| 4 | 49.8 | 42.6 | 49.7 |
| 5 | 48.7 | 49.3 | 52.2 |
| Avg | 43.7 | 43.1 | 46.3 |
Calculated strategy ablations (key takeaway)
Early experiments identified typical SAM failure modes for this task:
- Incomplete masks (unsegmented regions)
- Problematic “stuff” classes like walls/floors
- Centroid drift outside the object
- Over-fragmented (“Picasso”) pseudo-labels producing too many small regions
A critical finding was that filling unsegmented regions by majority voting (Max) is unreliable, so the pipeline uses Erd (hereditary) as the baseline.
A strong configuration found via ablation was Erd + Ns + nWm, which (on scenes 0–5, sampled evaluation) slightly improves average mIoU:
- Pseudo 3 cm average: 46.3
- SAM (Erd + Ns + nWm) average: 46.8
Full evaluation protocol
The full evaluation uses:
- Scenes 0–9
- Approximately 80% of valid frames per scene (excluding frames with unusable ground truth)
- Metric: mIoU against ScanNet ground truth
Quantitative results (ΔmIoU from pseudo-labels)
The core result is that refinement consistently improves pseudo-labels, and improvements are larger with coarser voxel maps (5 cm) because there is more room for correction.
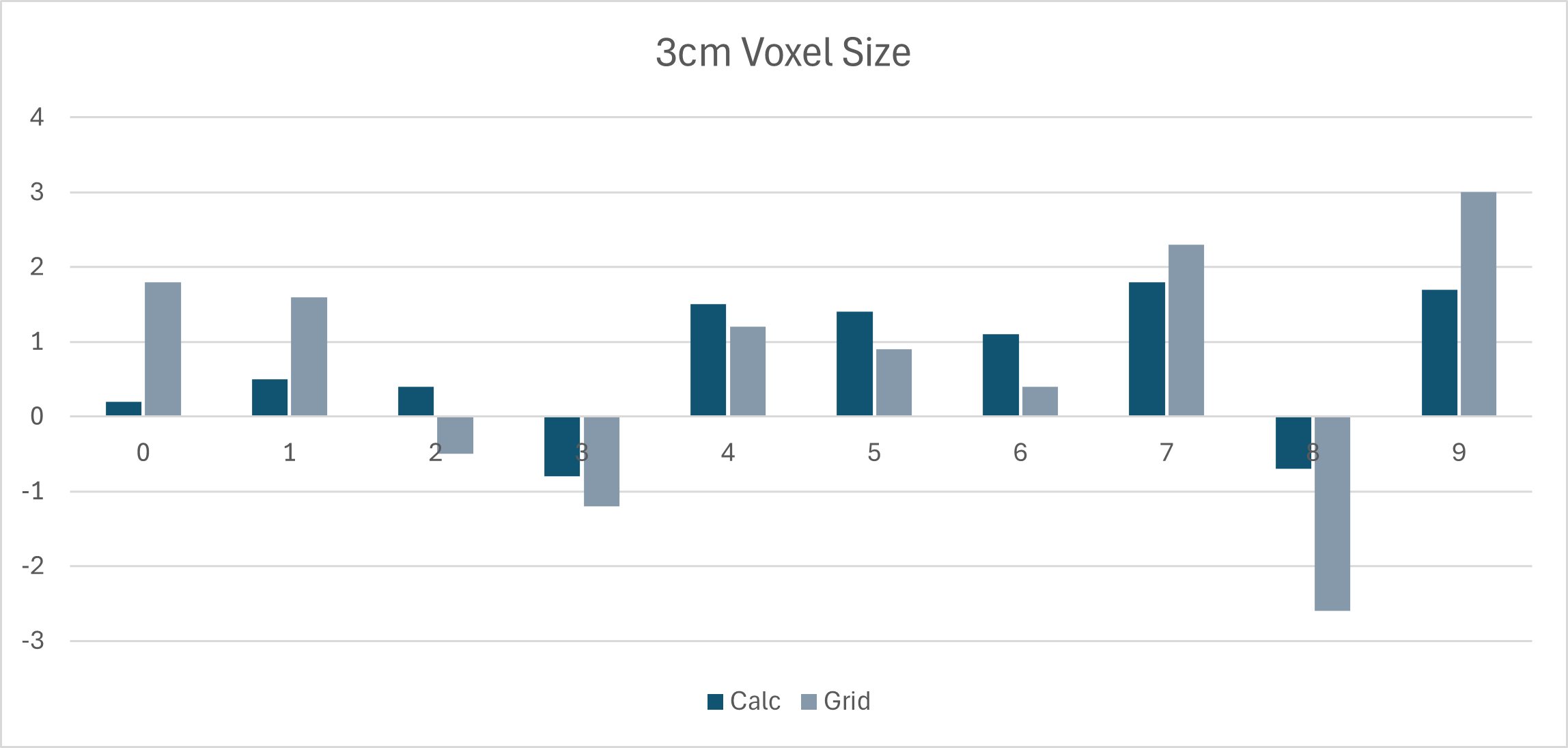
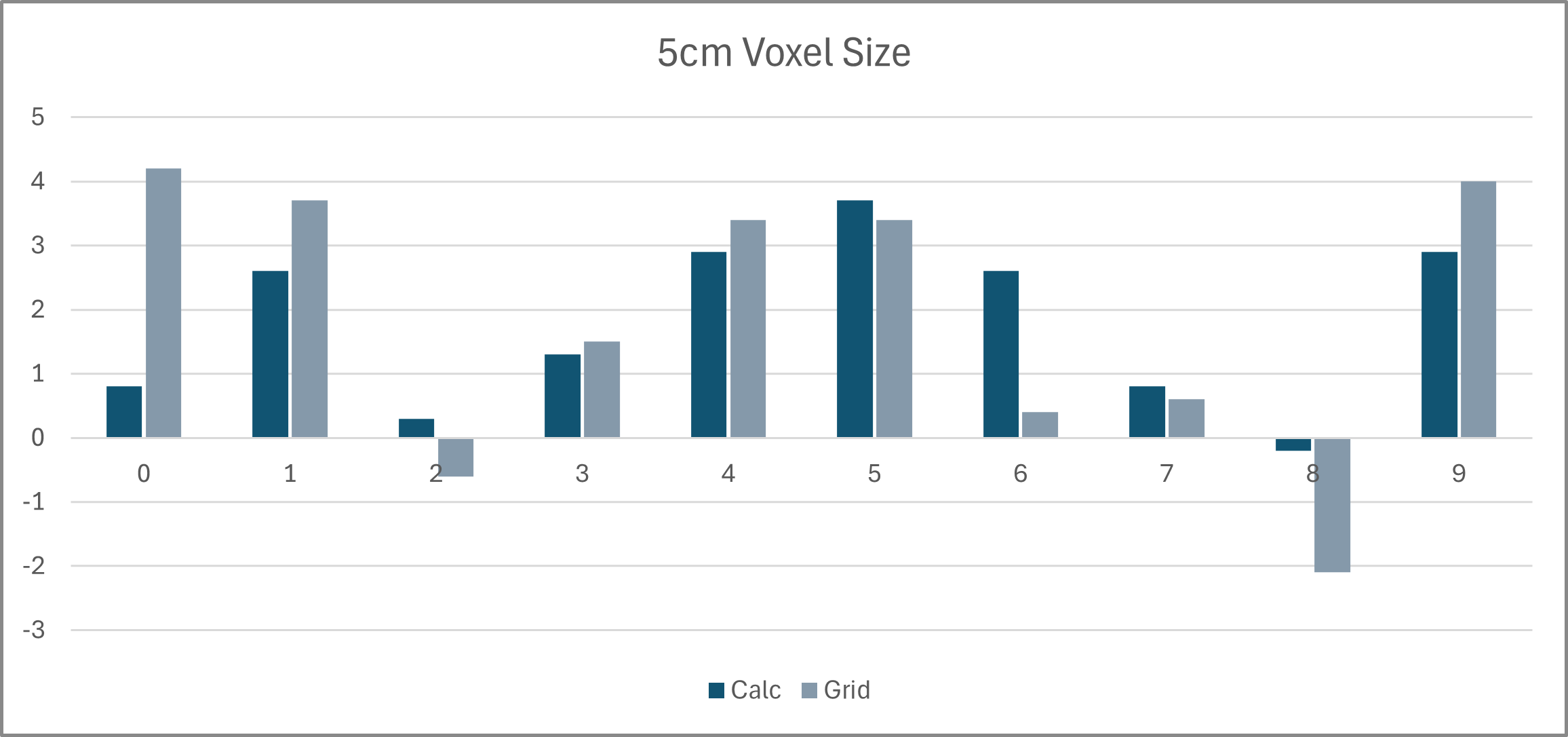
A summary across all scenes (mean and standard deviation of improvement):
| Voxel size | Prompting | Mean ΔmIoU | Std. dev. |
|---|---|---|---|
| 3 cm | Calculated | 0.71 | 0.90 |
| 3 cm | Grid | 0.69 | 1.62 |
| 5 cm | Calculated | 1.77 | 1.26 |
| 5 cm | Grid | 1.85 | 2.09 |
Interpretation:
- 5 cm benefits most from refinement (bigger improvements).
- Grid has slightly higher mean improvement, but much higher variance (more unstable).
- Calculated is more consistent and safer for deployment.
Qualitative Results
All qualitative examples below use the configuration that performed best in our experiments: 5 cm voxel size with high-resolution RGB.
Each row shows:
- Ground truth (ScanNet)
- Original pseudo-label
- SAM refinement with grid prompting
- SAM refinement with calculated prompting
Successful refinement
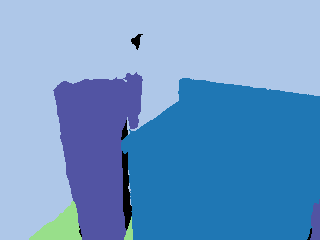 Ground truth |  Pseudo label |  Grid |  Calculated |
When calculated prompting is better
 Ground truth |  Pseudo label |  Grid |  Calculated |
When grid prompting is better
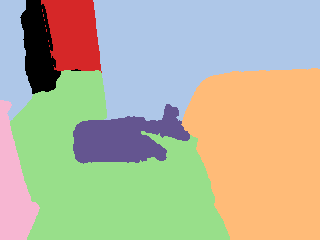 Ground truth | 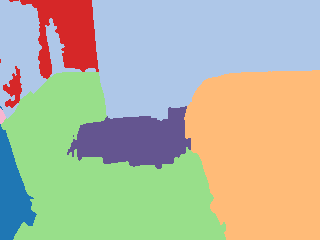 Pseudo label | 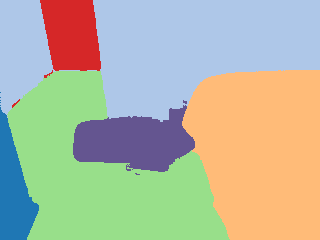 Grid | 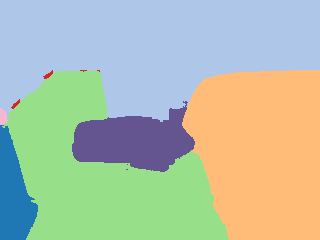 Calculated |
Failure case (SAM failure propagates)
 Ground truth |  Pseudo label |  Grid | 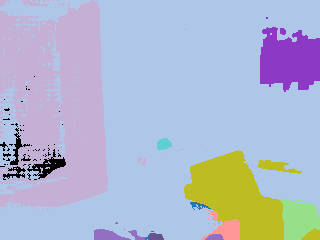 Calculated |
These examples highlight an important trade-off:
- Grid prompting can produce stronger refinements but is more vulnerable to SAM mistakes.
- Calculated prompting is more conservative and stable, but depends more on the initial pseudo-label quality.
Limitations
- SAM is not guaranteed to be correct: if SAM fails to segment a key object, refinement can worsen the label map.
- Sensitivity to prompt placement: small centroid or bounding-box misalignments can cause incorrect masks.
- Compute budget: high-resolution SAM runs can improve consistency, but cost more time.
Future Work
The most promising next step is to integrate the refinement stage into a fully online continual training loop:
- refine pseudo-labels with SAM2
- fine-tune DeepLabV3 online
- iterate as the robot explores
Additional robustness improvements suggested by the experiments:
- Uncertainty-aware prompt selection and rejection of risky masks
- Class-aware priors / constraints during mask-to-label fusion
- Dynamic prompting strategies conditioned on scene content
Conclusion
This project demonstrates that a foundation model like SAM2 can meaningfully improve pseudo-label quality in a 2D–3D UDA pipeline.
The strongest practical takeaway is that SAM refinement is especially valuable for coarser 5 cm voxel maps, where pseudo-labels are cheaper to produce but more degraded. With careful prompting and conservative fallback logic (Erd), SAM2 becomes a powerful component to reduce annotation needs and improve robustness in real-world robotic perception.