
Git RAG Assistant — Experience Report: Local-First Codebase Q&A with Evidence
Author: Lorenzo Signorelli
Abstract
This project is an experience report on building a local-first RAG assistant for software repositories. The objective was to explore a simple question: can a small, local pipeline help you understand an unfamiliar codebase while staying trustworthy?
The design goal was not “better prose”, but auditable answers: every response should be accompanied by the exact snippets used.
Why this experiment
In real projects, the hardest part of reading a new codebase is orientation:
- “Where is authentication handled?”
- “Which module owns configuration?”
- “Where does this request flow go next?”
Search tools return matches; LLMs return explanations. This work focuses on the boundary between the two: explanations constrained by retrieved evidence.
Constraints:
- Local-first: repositories stay on disk, on your machine.
- Evidence-first: answers must be verifiable without trust.
- Consumer hardware: indexing can be heavy, asking should be fast.
Baseline workflow
- Select a repository
- Index it once
- Ask questions while exploring
- Verify the answer by reading the attached evidence
Models used (defaults)
I deliberately kept the defaults conservative and local:
- Embeddings:
sentence-transformers/all-mpnet-base-v2 - LLM inference: Ollama with
qwen2.5:7b
The same Ollama model is used both for:
- producing the final answer
- running a lightweight “navigator” step (explained below)
What I built, as a sequence of decisions
1) Make the repository “quotable”
The first requirement was not intelligence, but traceability. The index had to preserve:
- file paths
- stable chunk boundaries
- line ranges (so citations point to something you can open)
This immediately improved the UX because the assistant could stop being “confident” and start being “specific”.
2) Force evidence into the answer
Once retrieval was in place, the strongest product decision was to make evidence visible by default.
The assistant’s response includes an explicit sources block with the quoted snippets.
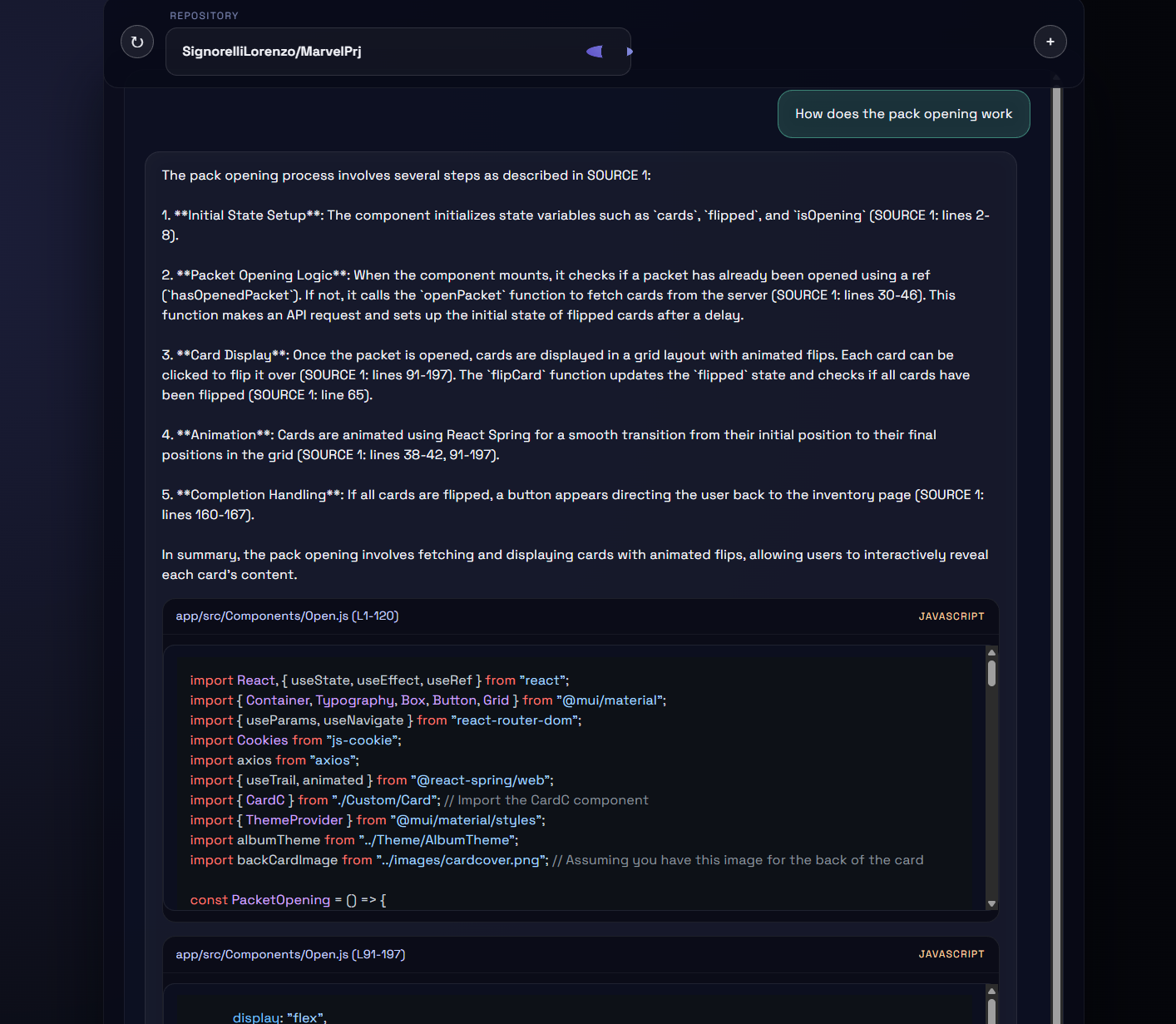
What changed in practice:
- Users spent less time arguing with the assistant.
- Wrong answers became useful anyway (they still pointed somewhere in the repo).
3) Deal with the “where is X?” failure mode
A recurring observation was that location/structure questions behave differently than implementation questions.
Even with good embeddings, raw code chunks can be noisy for queries like “where is auth?”. The project improved this by indexing structure signals alongside code:
- lightweight file-level summaries (imports and top-level symbols)
- directory-level summaries (what’s inside a folder)
This gave retrieval a better handle on “map-like” questions.
4) Constrain retrieval before it happens
On larger repositories, retrieval can still drift: the embedding search may surface chunks that are semantically related but not usefully located.
To reduce this, I introduced a small routing step:
- generate a compact “repo map”
- ask a small LLM call to output a shortlist of likely paths
- use that shortlist as a filter during retrieval
This was especially effective for broad questions (architecture, ownership, “where is…”), because it reduced off-topic context without growing the prompt.
Findings
- Evidence beats persuasion: attaching sources changed the trust model from “believe the assistant” to “inspect the proof”.
- Structure is a first-class signal: summaries improved location queries more than changing the generator.
- Latency is a UX constraint: embedding the question once and keeping prompts small made the system feel interactive.
- Local-first shapes everything: you optimize for batching, caching, and predictable artifacts.
Limitations
- Some questions are inherently ambiguous (“auth module” might be multiple layers).
- Indexing is still a deliberate step (not yet incremental).
- Summaries are heuristic and won’t capture deeper semantics like call graphs.